Mạnh Quân✔
Writer
Tại sao tác nhân AI luôn hoạt động không ổn định? Nhóm AI của Google Cloud đã công bố một công thức toán học để tối đa hóa tỷ lệ thành công của thiết kế tác nhân.
Bằng cách nâng tầm thiết kế tác nhân AI từ một quá trình thử nghiệm mang tính kinh nghiệm lên một phương pháp kỹ thuật hệ thống có thể định lượng thông qua một khuôn khổ xác suất thống nhất, nghiên cứu này cho thấy rằng sự hợp tác giữa nhiều tác nhân về bản chất là một quá trình tìm kiếm năng động về xác suất thành công.
Ngày nay, các nhà phát triển đang tạo ra đủ loại tác nhân thông minh bằng cách sử dụng nhiều framework khác nhau. Một số dựa trên vòng lặp ReAct, một số dựa vào cấu trúc đồ thị phức tạp, và một số đang cố gắng xây dựng các nhóm đa tác nhân.
Mọi người đều hành động dựa trên trực giác, liên tục cố gắng và thất bại trong việc điều chỉnh các gợi ý và sửa đổi các quy trình nhằm mục đích làm cho các tác nhân thông minh này trở nên thông minh hơn và ổn định hơn khi xử lý các nhiệm vụ phức tạp.
Mô hình phát triển này rất giống với thuật giả kim sơ khai và mang đậm tính thực nghiệm.
Chúng ta biết rằng việc thêm dấu chấm nhắc sẽ giúp mọi thứ hoạt động tốt hơn, trong khi việc thay đổi một tham số sẽ làm cho mọi thứ trở nên rắc rối, nhưng không ai có thể chắc chắn lý do tại sao, chứ đừng nói đến việc định lượng sự đánh đổi giữa các kiến trúc khác nhau.
Nhóm nghiên cứu AI của Google Cloud đang cố gắng thiết lập một bộ số liệu thống nhất cho toàn bộ lĩnh vực tác nhân thông minh. Họ đề xuất rằng dù kiến trúc của một tác nhân thông minh có phức tạp đến đâu, bản chất của nó vẫn có thể được trừu tượng hóa thành một quy trình xác suất.
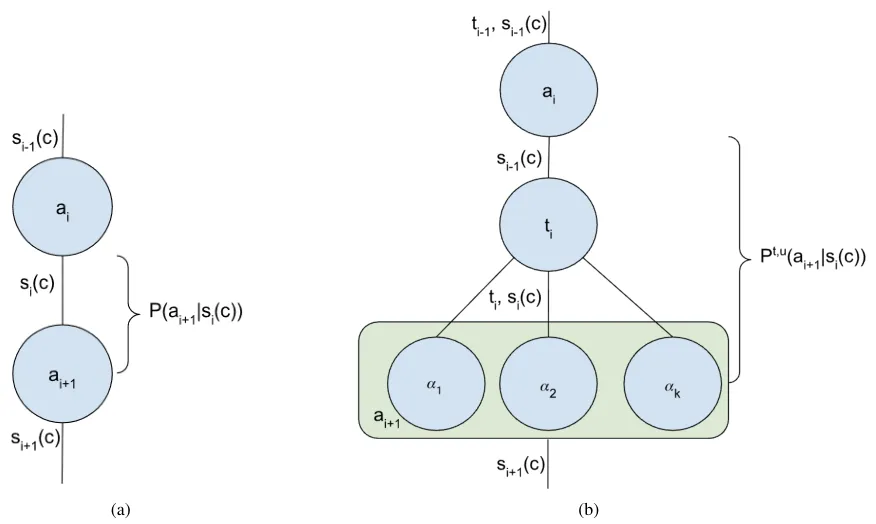
Mục tiêu cốt lõi của một tác nhân thông minh rất đơn giản: với một bối cảnh ban đầu, tối đa hóa xác suất thực hiện một loạt các hành động cụ thể để đạt được mục tiêu đã định trước.
Điều này nghe có vẻ đơn giản, nhưng một khi chúng ta biểu diễn nó dưới dạng toán học của chuỗi Markov, chúng ta có thể thấy được sự thật ẩn giấu đằng sau mã lập trình.
Khung lý thuyết này không chỉ giải thích tại sao ReAct bị kẹt trong vòng lặp vô hạn, mà còn tiết lộ các nguyên tắc toán học đằng sau sức mạnh của hệ thống đa tác tử - chúng tạo ra các mức độ tự do hoàn toàn mới, cho phép hệ thống có khả năng tối ưu hóa động tỷ lệ thành công trong quá trình thực thi.
Chúng ta không còn cần phải điều chỉnh các lời nhắc một cách mù quáng nữa; chúng ta có thể thao tác chính xác mô hình xác suất của tác nhân, giống như một kỹ sư điều chỉnh cần điều khiển.
Từ góc độ toán học, hoạt động của một tác nhân thông minh là một chuỗi liên kết bởi các xác suất.
Mỗi thao tác không mang tính xác định, mà thay vào đó, nó lựa chọn hành động tiếp theo với một xác suất nhất định dựa trên ngữ cảnh hiện tại và trạng thái của bước trước đó.

Đây chính là cái được gọi là chuỗi Markov.
Lấy mô hình ReAct kinh điển làm ví dụ, về cơ bản nó là một vòng lặp suy nghĩ-hành động. Mô hình đầu tiên tạo ra một ý tưởng, sau đó thực hiện một hành động dựa trên ý tưởng đó, và cuối cùng quan sát kết quả và cập nhật trạng thái.

Mặc dù kiến trúc ReAct rất thanh lịch, nhưng nó lại mắc phải một lỗi toán học nghiêm trọng.
Về bản chất, đó là một quá trình bước đi ngẫu nhiên.
Tác nhân di chuyển trong một không gian hành động rộng lớn, và mỗi bước đi của nó đều tiềm ẩn nguy cơ sai lệch xác suất.
Nếu chuỗi các thao tác cần thực hiện rất dài, hoặc nếu có nhiều thao tác tùy chọn cho mỗi bước, thì xác suất hoàn thành toàn bộ quy trình một cách thành công sẽ giảm theo cấp số mũ.
Các bước đi ngẫu nhiên không bị ràng buộc dễ dẫn đến tình trạng không hội tụ, điều mà chúng ta thường gọi là các tác nhân bị mắc kẹt trong vòng lặp vô hạn hoặc lạc lối ngày càng xa hơn trong ảo giác.
Đây chính là lý do cơ bản tại sao các tác nhân thông minh đơn lẻ hiện nay gặp khó khăn trong việc xử lý các nhiệm vụ cực kỳ dài và phức tạp: chuỗi xác suất càng dài, sai số tích lũy càng lớn, và xác suất thành công cuối cùng bị giảm xuống mức không đáng kể.
Các nhà nghiên cứu của Google đã giới thiệu một khái niệm tuyệt vời – Độ tự do (Degrees of Freedom).
Trong kỹ thuật, bậc tự do biểu thị số lượng tham số của một hệ thống có thể thay đổi độc lập.
Trong thiết kế tác nhân thông minh, bậc tự do giống như các núm vặn và cần gạt mà các nhà phát triển có thể điều chỉnh. Càng nhiều bậc tự do, chúng ta càng có nhiều không gian để tối ưu hóa hiệu suất hệ thống.
Chúng ta hãy chuyển sự chú ý sang kiến trúc luồng điều khiển.
Không giống như cách tiếp cận tự do của ReAct, kiến trúc điều khiển luồng giới hạn phạm vi hoạt động của tác nhân ở mỗi bước thông qua một đồ thị hoặc máy trạng thái được xác định trước.
Cách tiếp cận này trực tiếp loại bỏ hầu hết các đường dẫn sai. Bằng cách chia nhỏ nhiệm vụ một cách nhân tạo, chúng ta chia một chuỗi dài, có xác suất thấp thành nhiều chuỗi con ngắn, có xác suất cao hơn.
Trong kiến trúc luồng điều khiển, các nhà phát triển không chỉ có thể tối ưu hóa các lời nhắc ban đầu mà còn có thể tùy chỉnh lời nhắc cho từng nút trong đồ thị, và thậm chí trang bị cho các nút khác nhau các công cụ mô hình khác nhau.

Ở chế độ ReAct, hầu hết các cần gạt đều bị khóa (Static/Global), trong khi ở chế độ Control Flow, chúng được mở khóa từng cái một (Dynamic/Partition/Switch).
Mặc dù điều khiển luồng rất mạnh mẽ, nhưng nó vẫn phụ thuộc vào các quy tắc do nhà phát triển định nghĩa trước. Tất cả các phân chia đường dẫn và thiết kế nút cần được mã hóa cứng trước khi chạy. Điều này có nghĩa là giới hạn trên của hệ thống bị khóa trong phạm vi nhận thức của nhà phát triển.
Sự thay đổi chất lượng thực sự xảy ra trong các hệ thống đa tác tử (MAS).
Hệ thống đa tác nhân không chỉ đơn thuần là việc cho nhiều tác nhân trò chuyện trong một nhóm chat. Trong khuôn khổ xác suất, chúng mang đến một mức độ tự do chưa từng có – xác suất hợp tác.
Trong hệ thống đơn tác nhân, ngữ cảnh được môi trường cung cấp một cách thụ động. Tuy nhiên, trong hệ thống đa tác nhân, ngữ cảnh được các tác nhân khác chủ động tạo ra. Điều này có nghĩa là hệ thống có khả năng tìm kiếm ngữ cảnh tối ưu một cách năng động.
Khi hai tác nhân thông minh hợp tác hoặc đàm phán, thực chất chúng đang tìm kiếm một trạng thái trung gian giúp tối đa hóa xác suất thành công tổng thể thông qua sự tương tác liên tục.
Chúng ta có thể xem đây như một cuộc tìm kiếm chung trong không gian xác suất đa chiều.
Tác nhân A không trực tiếp thực hiện nhiệm vụ, mà điều chỉnh trạng thái của Tác nhân B bằng cách tạo ra ngữ cảnh cho đến khi Tác nhân B đạt được điểm tối ưu cục bộ với tỷ lệ thành công rất cao.
Cơ chế này loại bỏ nhu cầu huấn luyện lại mô hình và mã hóa thủ công các quy tắc. Nó tận dụng khả năng suy luận vốn có của mô hình để tự động điều chỉnh phù hợp với yêu cầu của nhiệm vụ trong quá trình thực thi.
Đây là lý do tại sao các hệ thống đa tác nhân thường có thể giải quyết được những vấn đề mà các tác nhân đơn lẻ không thể xử lý.
Bằng cách chia nhỏ các nhiệm vụ lớn và cho phép các tác nhân tự điều chỉnh ngữ cảnh, về cơ bản chúng ta đang đánh đổi khả năng tính toán lấy tính xác suất. Chúng ta tiêu tốn nhiều tài nguyên suy luận hơn trong quá trình thực thi để đổi lấy một con đường dẫn đến mục tiêu mang tính xác định hơn.
Bảng dưới đây tóm tắt chi tiết cách các nhà phát triển đã dần mở rộng quyền kiểm soát của họ từ ReAct sang cộng tác đa tác nhân.


Hãy tưởng tượng một quy trình xử lý tác vụ theo thứ bậc. Tác nhân 1 (ví dụ: người quản lý dự án) không trực tiếp viết mã; hành động của nó là tạo ra một chỉ thị cho Tác nhân 2 (lập trình viên). Chỉ thị này tạo thành ngữ cảnh cho Tác nhân 2.
Nếu tác nhân 2 nhận thấy chỉ thị không rõ ràng, nó sẽ không đưa ra phỏng đoán như một tác nhân đơn lẻ (điều này sẽ dẫn đến sự sụp đổ xác suất), mà thay vào đó sẽ cung cấp ngữ cảnh cho tác nhân 1. Quá trình này có thể được lặp lại.
Trong sơ đồ tương tác này, các phần kết nối màu tím P(cL|aL) và P(cK|aK) là cốt lõi của kiến trúc này. Chúng thể hiện chất lượng giao tiếp giữa các tác nhân.
Về bản chất, hình thức giao tiếp này là một dạng nhắc nhở tự động không cần sự can thiệp của con người. Tác nhân 1 liên tục cố gắng điều chỉnh các lời nhắc được đưa ra cho Tác nhân 2 cho đến khi tỷ lệ thành công của Tác nhân 2 đạt đến một ngưỡng nhất định.
Trong toán học, đàm phán hay hợp tác, như chúng ta thường nói đến, là một quá trình tìm kiếm tối ưu hóa hai yếu tố xác suất này.
Bằng cách cho phép nhiều tương tác, hệ thống đã khám phá những con đường tiềm ẩn trong không gian hành động và tìm ra lối tắt dẫn đến thành công mà không thể nhìn thấy từ góc độ tĩnh.
Khả năng tìm kiếm này mang lại cho hệ thống độ bền cực kỳ cao.
Ngay cả khi đối mặt với những nhiệm vụ chưa từng thấy, miễn là các tác nhân thông minh có thể điều chỉnh sự hiểu biết của chúng thông qua giao tiếp, chúng có thể chủ động xây dựng các giải pháp.
Đây là lý do tại sao Giao thức giữa các tác nhân ( A2A) được sử dụng.Các tiêu chuẩn giao thức như vậy trở nên quan trọng vì chúng điều chỉnh các kênh trao đổi xác suất này.
Mặc dù các hệ thống đa tác nhân có thể cải thiện đáng kể tỷ lệ thành công của các nhiệm vụ phức tạp, nhưng việc áp dụng hợp tác một cách thiếu kiểm soát có thể dẫn đến các vấn đề nghiêm trọng về hiệu quả.
Mỗi lần bắt tay và đàm phán giữa các tác nhân thông minh đều dẫn đến sự gia tăng độ trễ mạng, mức tiêu thụ token và chi phí tính toán.
Do đó, nhóm của Google đã đề xuất một hàm mục tiêu được sửa đổi.
Chúng ta không thể chỉ theo đuổi mục tiêu tối đa hóa tỷ lệ thành công; chúng ta cũng phải xem xét chi phí hợp tác.
Hàm mục tiêu mới đưa ra một thuật ngữ điều chỉnh:

Ở đây, CollabCost đại diện cho tổng chi phí, bao gồm độ trễ, phí token và độ phức tạp của hệ thống, trong khi λ là một siêu tham số được sử dụng để điều chỉnh độ nhạy của chúng ta đối với chi phí.
Công thức này đóng vai trò là nguyên tắc hướng dẫn cho thực tiễn kỹ thuật. Nó nhắc nhở các nhà thiết kế rằng trong khi theo đuổi trí thông minh cao, họ cũng phải hạn chế sự rườm rà của hệ thống.
Nếu một nhiệm vụ đơn giản có thể được giải quyết nhanh chóng bởi một tác nhân ReAct duy nhất, hệ thống không nên khởi động một quy trình đàm phán đa tác nhân phức tạp.
Một kiến trúc tác nhân thông minh xuất sắc cần có khả năng thích ứng, tự động điều chỉnh trọng số của λ theo độ khó của nhiệm vụ, hoặc cân bằng trọng số này theo kịch bản ứng dụng trong giai đoạn thiết kế.
Thực chất, đây là việc tìm ra điểm cân bằng giữa xác suất cao và hiệu quả cao.
Một hệ thống được thiết kế tốt cần giảm thiểu tối đa sự tương tác không cần thiết giữa các tác nhân, đồng thời đảm bảo tỷ lệ hoàn thành nhiệm vụ ở mức chấp nhận được.
Từ lâu, việc phát triển tác nhân chủ yếu dựa vào trực giác của nhà phát triển và việc gỡ lỗi lặp đi lặp lại. Chúng ta biết rằng Giao thức Ngữ cảnh Mô hình ( MCP)...Nó hữu ích. Tôi biết rằng CoT (Mind Chain) có thể cải thiện khả năng tư duy logic, nhưng những điểm kiến thức này lại rải rác.
Bài viết này từ Google Cloud AI đã xâu chuỗi những viên ngọc rải rác đó lại với nhau thành một chuỗi vòng cổ.
Bằng cách giới thiệu các khái niệm như chuỗi xác suất, bậc tự do, xác suất hợp tác và chi phí hợp tác, họ đã xây dựng một khuôn khổ logic chặt chẽ cho việc thiết kế các tác nhân thông minh.
Nó mở đường cho thiết kế tự động hóa trong tương lai.
Vì hoạt động của các tác nhân thông minh có thể được định lượng bằng các công thức toán học, chúng ta có thể thiết kế các thuật toán để tự động tìm kiếm cấu trúc tối ưu của tác nhân thông minh, tự động cân bằng tỷ lệ thành công và chi phí, và thậm chí cho phép tác nhân thông minh tự tiến hóa trong quá trình hoạt động.
Tài liệu tham khảo:
Bằng cách nâng tầm thiết kế tác nhân AI từ một quá trình thử nghiệm mang tính kinh nghiệm lên một phương pháp kỹ thuật hệ thống có thể định lượng thông qua một khuôn khổ xác suất thống nhất, nghiên cứu này cho thấy rằng sự hợp tác giữa nhiều tác nhân về bản chất là một quá trình tìm kiếm năng động về xác suất thành công.
Tái cấu trúc toán học: Chuyển đổi trực giác thành các định luật kỹ thuật
Chúng ta đã chứng kiến một bước tiến vượt bậc từ việc tạo văn bản đơn giản đến các tác nhân AI có khả năng lập kế hoạch tự động và gọi công cụ.Ngày nay, các nhà phát triển đang tạo ra đủ loại tác nhân thông minh bằng cách sử dụng nhiều framework khác nhau. Một số dựa trên vòng lặp ReAct, một số dựa vào cấu trúc đồ thị phức tạp, và một số đang cố gắng xây dựng các nhóm đa tác nhân.
Mọi người đều hành động dựa trên trực giác, liên tục cố gắng và thất bại trong việc điều chỉnh các gợi ý và sửa đổi các quy trình nhằm mục đích làm cho các tác nhân thông minh này trở nên thông minh hơn và ổn định hơn khi xử lý các nhiệm vụ phức tạp.
Mô hình phát triển này rất giống với thuật giả kim sơ khai và mang đậm tính thực nghiệm.
Chúng ta biết rằng việc thêm dấu chấm nhắc sẽ giúp mọi thứ hoạt động tốt hơn, trong khi việc thay đổi một tham số sẽ làm cho mọi thứ trở nên rắc rối, nhưng không ai có thể chắc chắn lý do tại sao, chứ đừng nói đến việc định lượng sự đánh đổi giữa các kiến trúc khác nhau.
Nhóm nghiên cứu AI của Google Cloud đang cố gắng thiết lập một bộ số liệu thống nhất cho toàn bộ lĩnh vực tác nhân thông minh. Họ đề xuất rằng dù kiến trúc của một tác nhân thông minh có phức tạp đến đâu, bản chất của nó vẫn có thể được trừu tượng hóa thành một quy trình xác suất.
Mục tiêu cốt lõi của một tác nhân thông minh rất đơn giản: với một bối cảnh ban đầu, tối đa hóa xác suất thực hiện một loạt các hành động cụ thể để đạt được mục tiêu đã định trước.
Điều này nghe có vẻ đơn giản, nhưng một khi chúng ta biểu diễn nó dưới dạng toán học của chuỗi Markov, chúng ta có thể thấy được sự thật ẩn giấu đằng sau mã lập trình.
Khung lý thuyết này không chỉ giải thích tại sao ReAct bị kẹt trong vòng lặp vô hạn, mà còn tiết lộ các nguyên tắc toán học đằng sau sức mạnh của hệ thống đa tác tử - chúng tạo ra các mức độ tự do hoàn toàn mới, cho phép hệ thống có khả năng tối ưu hóa động tỷ lệ thành công trong quá trình thực thi.
Chúng ta không còn cần phải điều chỉnh các lời nhắc một cách mù quáng nữa; chúng ta có thể thao tác chính xác mô hình xác suất của tác nhân, giống như một kỹ sư điều chỉnh cần điều khiển.
Từ góc độ toán học, hoạt động của một tác nhân thông minh là một chuỗi liên kết bởi các xác suất.
Mỗi thao tác không mang tính xác định, mà thay vào đó, nó lựa chọn hành động tiếp theo với một xác suất nhất định dựa trên ngữ cảnh hiện tại và trạng thái của bước trước đó.
Đây chính là cái được gọi là chuỗi Markov.
Lấy mô hình ReAct kinh điển làm ví dụ, về cơ bản nó là một vòng lặp suy nghĩ-hành động. Mô hình đầu tiên tạo ra một ý tưởng, sau đó thực hiện một hành động dựa trên ý tưởng đó, và cuối cùng quan sát kết quả và cập nhật trạng thái.
Mặc dù kiến trúc ReAct rất thanh lịch, nhưng nó lại mắc phải một lỗi toán học nghiêm trọng.
Về bản chất, đó là một quá trình bước đi ngẫu nhiên.
Tác nhân di chuyển trong một không gian hành động rộng lớn, và mỗi bước đi của nó đều tiềm ẩn nguy cơ sai lệch xác suất.
Nếu chuỗi các thao tác cần thực hiện rất dài, hoặc nếu có nhiều thao tác tùy chọn cho mỗi bước, thì xác suất hoàn thành toàn bộ quy trình một cách thành công sẽ giảm theo cấp số mũ.
Các bước đi ngẫu nhiên không bị ràng buộc dễ dẫn đến tình trạng không hội tụ, điều mà chúng ta thường gọi là các tác nhân bị mắc kẹt trong vòng lặp vô hạn hoặc lạc lối ngày càng xa hơn trong ảo giác.
Đây chính là lý do cơ bản tại sao các tác nhân thông minh đơn lẻ hiện nay gặp khó khăn trong việc xử lý các nhiệm vụ cực kỳ dài và phức tạp: chuỗi xác suất càng dài, sai số tích lũy càng lớn, và xác suất thành công cuối cùng bị giảm xuống mức không đáng kể.
Mức độ tự do: đòn bẩy điều khiển các tác nhân thông minh
Để giải quyết vấn đề suy giảm xác suất do các bước đi ngẫu nhiên gây ra, chúng ta cần thêm các phương pháp can thiệp vào chuỗi xác suất.Các nhà nghiên cứu của Google đã giới thiệu một khái niệm tuyệt vời – Độ tự do (Degrees of Freedom).
Trong kỹ thuật, bậc tự do biểu thị số lượng tham số của một hệ thống có thể thay đổi độc lập.
Trong thiết kế tác nhân thông minh, bậc tự do giống như các núm vặn và cần gạt mà các nhà phát triển có thể điều chỉnh. Càng nhiều bậc tự do, chúng ta càng có nhiều không gian để tối ưu hóa hiệu suất hệ thống.
Chúng ta hãy chuyển sự chú ý sang kiến trúc luồng điều khiển.
Không giống như cách tiếp cận tự do của ReAct, kiến trúc điều khiển luồng giới hạn phạm vi hoạt động của tác nhân ở mỗi bước thông qua một đồ thị hoặc máy trạng thái được xác định trước.
Cách tiếp cận này trực tiếp loại bỏ hầu hết các đường dẫn sai. Bằng cách chia nhỏ nhiệm vụ một cách nhân tạo, chúng ta chia một chuỗi dài, có xác suất thấp thành nhiều chuỗi con ngắn, có xác suất cao hơn.
Trong kiến trúc luồng điều khiển, các nhà phát triển không chỉ có thể tối ưu hóa các lời nhắc ban đầu mà còn có thể tùy chỉnh lời nhắc cho từng nút trong đồ thị, và thậm chí trang bị cho các nút khác nhau các công cụ mô hình khác nhau.
Ở chế độ ReAct, hầu hết các cần gạt đều bị khóa (Static/Global), trong khi ở chế độ Control Flow, chúng được mở khóa từng cái một (Dynamic/Partition/Switch).
Mặc dù điều khiển luồng rất mạnh mẽ, nhưng nó vẫn phụ thuộc vào các quy tắc do nhà phát triển định nghĩa trước. Tất cả các phân chia đường dẫn và thiết kế nút cần được mã hóa cứng trước khi chạy. Điều này có nghĩa là giới hạn trên của hệ thống bị khóa trong phạm vi nhận thức của nhà phát triển.
Sự thay đổi chất lượng thực sự xảy ra trong các hệ thống đa tác tử (MAS).
Hệ thống đa tác nhân không chỉ đơn thuần là việc cho nhiều tác nhân trò chuyện trong một nhóm chat. Trong khuôn khổ xác suất, chúng mang đến một mức độ tự do chưa từng có – xác suất hợp tác.
Trong hệ thống đơn tác nhân, ngữ cảnh được môi trường cung cấp một cách thụ động. Tuy nhiên, trong hệ thống đa tác nhân, ngữ cảnh được các tác nhân khác chủ động tạo ra. Điều này có nghĩa là hệ thống có khả năng tìm kiếm ngữ cảnh tối ưu một cách năng động.
Khi hai tác nhân thông minh hợp tác hoặc đàm phán, thực chất chúng đang tìm kiếm một trạng thái trung gian giúp tối đa hóa xác suất thành công tổng thể thông qua sự tương tác liên tục.
Chúng ta có thể xem đây như một cuộc tìm kiếm chung trong không gian xác suất đa chiều.
Tác nhân A không trực tiếp thực hiện nhiệm vụ, mà điều chỉnh trạng thái của Tác nhân B bằng cách tạo ra ngữ cảnh cho đến khi Tác nhân B đạt được điểm tối ưu cục bộ với tỷ lệ thành công rất cao.
Cơ chế này loại bỏ nhu cầu huấn luyện lại mô hình và mã hóa thủ công các quy tắc. Nó tận dụng khả năng suy luận vốn có của mô hình để tự động điều chỉnh phù hợp với yêu cầu của nhiệm vụ trong quá trình thực thi.
Đây là lý do tại sao các hệ thống đa tác nhân thường có thể giải quyết được những vấn đề mà các tác nhân đơn lẻ không thể xử lý.
Bằng cách chia nhỏ các nhiệm vụ lớn và cho phép các tác nhân tự điều chỉnh ngữ cảnh, về cơ bản chúng ta đang đánh đổi khả năng tính toán lấy tính xác suất. Chúng ta tiêu tốn nhiều tài nguyên suy luận hơn trong quá trình thực thi để đổi lấy một con đường dẫn đến mục tiêu mang tính xác định hơn.
Bảng dưới đây tóm tắt chi tiết cách các nhà phát triển đã dần mở rộng quyền kiểm soát của họ từ ReAct sang cộng tác đa tác nhân.
Bản chất của sự hợp tác: trao đổi tính toán để có được sự chắc chắn.
P(cL|aL) và P(cK|aK) được giới thiệu bởi sự hợp tác đa tác nhân giống như chất bôi trơn và chất điều chỉnh trên chuỗi xác suất.Hãy tưởng tượng một quy trình xử lý tác vụ theo thứ bậc. Tác nhân 1 (ví dụ: người quản lý dự án) không trực tiếp viết mã; hành động của nó là tạo ra một chỉ thị cho Tác nhân 2 (lập trình viên). Chỉ thị này tạo thành ngữ cảnh cho Tác nhân 2.
Nếu tác nhân 2 nhận thấy chỉ thị không rõ ràng, nó sẽ không đưa ra phỏng đoán như một tác nhân đơn lẻ (điều này sẽ dẫn đến sự sụp đổ xác suất), mà thay vào đó sẽ cung cấp ngữ cảnh cho tác nhân 1. Quá trình này có thể được lặp lại.
Trong sơ đồ tương tác này, các phần kết nối màu tím P(cL|aL) và P(cK|aK) là cốt lõi của kiến trúc này. Chúng thể hiện chất lượng giao tiếp giữa các tác nhân.
Về bản chất, hình thức giao tiếp này là một dạng nhắc nhở tự động không cần sự can thiệp của con người. Tác nhân 1 liên tục cố gắng điều chỉnh các lời nhắc được đưa ra cho Tác nhân 2 cho đến khi tỷ lệ thành công của Tác nhân 2 đạt đến một ngưỡng nhất định.
Trong toán học, đàm phán hay hợp tác, như chúng ta thường nói đến, là một quá trình tìm kiếm tối ưu hóa hai yếu tố xác suất này.
Bằng cách cho phép nhiều tương tác, hệ thống đã khám phá những con đường tiềm ẩn trong không gian hành động và tìm ra lối tắt dẫn đến thành công mà không thể nhìn thấy từ góc độ tĩnh.
Khả năng tìm kiếm này mang lại cho hệ thống độ bền cực kỳ cao.
Ngay cả khi đối mặt với những nhiệm vụ chưa từng thấy, miễn là các tác nhân thông minh có thể điều chỉnh sự hiểu biết của chúng thông qua giao tiếp, chúng có thể chủ động xây dựng các giải pháp.
Đây là lý do tại sao Giao thức giữa các tác nhân ( A2A) được sử dụng.Các tiêu chuẩn giao thức như vậy trở nên quan trọng vì chúng điều chỉnh các kênh trao đổi xác suất này.
Vấn đề không chỉ nằm ở lợi ích: mà còn ở chi phí của sự hợp tác.
Không có bữa trưa nào là miễn phí; việc tăng xác suất thành công đòi hỏi phải tiêu tốn nguồn lực.Mặc dù các hệ thống đa tác nhân có thể cải thiện đáng kể tỷ lệ thành công của các nhiệm vụ phức tạp, nhưng việc áp dụng hợp tác một cách thiếu kiểm soát có thể dẫn đến các vấn đề nghiêm trọng về hiệu quả.
Mỗi lần bắt tay và đàm phán giữa các tác nhân thông minh đều dẫn đến sự gia tăng độ trễ mạng, mức tiêu thụ token và chi phí tính toán.
Do đó, nhóm của Google đã đề xuất một hàm mục tiêu được sửa đổi.
Chúng ta không thể chỉ theo đuổi mục tiêu tối đa hóa tỷ lệ thành công; chúng ta cũng phải xem xét chi phí hợp tác.
Hàm mục tiêu mới đưa ra một thuật ngữ điều chỉnh:
Ở đây, CollabCost đại diện cho tổng chi phí, bao gồm độ trễ, phí token và độ phức tạp của hệ thống, trong khi λ là một siêu tham số được sử dụng để điều chỉnh độ nhạy của chúng ta đối với chi phí.
Công thức này đóng vai trò là nguyên tắc hướng dẫn cho thực tiễn kỹ thuật. Nó nhắc nhở các nhà thiết kế rằng trong khi theo đuổi trí thông minh cao, họ cũng phải hạn chế sự rườm rà của hệ thống.
Nếu một nhiệm vụ đơn giản có thể được giải quyết nhanh chóng bởi một tác nhân ReAct duy nhất, hệ thống không nên khởi động một quy trình đàm phán đa tác nhân phức tạp.
Một kiến trúc tác nhân thông minh xuất sắc cần có khả năng thích ứng, tự động điều chỉnh trọng số của λ theo độ khó của nhiệm vụ, hoặc cân bằng trọng số này theo kịch bản ứng dụng trong giai đoạn thiết kế.
Thực chất, đây là việc tìm ra điểm cân bằng giữa xác suất cao và hiệu quả cao.
Một hệ thống được thiết kế tốt cần giảm thiểu tối đa sự tương tác không cần thiết giữa các tác nhân, đồng thời đảm bảo tỷ lệ hoàn thành nhiệm vụ ở mức chấp nhận được.
Từ lâu, việc phát triển tác nhân chủ yếu dựa vào trực giác của nhà phát triển và việc gỡ lỗi lặp đi lặp lại. Chúng ta biết rằng Giao thức Ngữ cảnh Mô hình ( MCP)...Nó hữu ích. Tôi biết rằng CoT (Mind Chain) có thể cải thiện khả năng tư duy logic, nhưng những điểm kiến thức này lại rải rác.
Bài viết này từ Google Cloud AI đã xâu chuỗi những viên ngọc rải rác đó lại với nhau thành một chuỗi vòng cổ.
Bằng cách giới thiệu các khái niệm như chuỗi xác suất, bậc tự do, xác suất hợp tác và chi phí hợp tác, họ đã xây dựng một khuôn khổ logic chặt chẽ cho việc thiết kế các tác nhân thông minh.
Nó mở đường cho thiết kế tự động hóa trong tương lai.
Vì hoạt động của các tác nhân thông minh có thể được định lượng bằng các công thức toán học, chúng ta có thể thiết kế các thuật toán để tự động tìm kiếm cấu trúc tối ưu của tác nhân thông minh, tự động cân bằng tỷ lệ thành công và chi phí, và thậm chí cho phép tác nhân thông minh tự tiến hóa trong quá trình hoạt động.
Tài liệu tham khảo: